一個功能所執行的商業邏輯可能會非常複雜,在微服務架構下,這些邏輯通常會跨越多個服務來完成。在這種情況下,要釐清整個過程中經過了哪些服務、效能瓶頸出現在何處,以及每個服務中具體處理了哪些任務,就需要使用 追蹤(Trace) 技術。
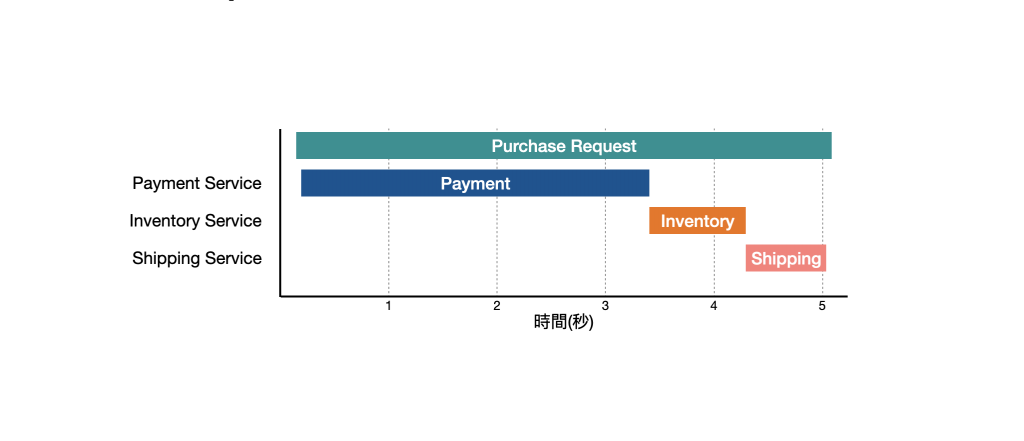
Trace 主要關注的是 單次請求的處理過程,透過它,我們可以了解每個服務的執行時間與依賴關係,進而找出效能瓶頸或故障。舉個例子,假設使用者在購物網站發起購買需求時,透過 Trace 可以將經過的支付服務、庫存服務與物流服務執行時間都記錄下來,就可以很清楚地知道哪個服務造成整個流程緩慢,迅速定位問題。
遙測數據(Telemetry) 是指從遠端系統中收集的測量值或是利於分析的資料,主要用於監控、診斷系統。Telemetry 共有三大種類:
那 Telemetry 可以怎麼搭配使用來找出問題呢?這邊舉個例子,假設有一個電商平台,由多個服務組成,如:支付服務、庫存服務以及物流服務。在某天 Slack 跳了警告通知,告知維運人員「訂單處理速度緩慢」,此時維運人員可以透過 Metrics 發現支付服務回應時間比平時還多,這時透過 Trace 發現,原來支付服務因為第三方金流服務回應緩慢導致整體訂單完成時間變長,最後,透過 Log 發現第三方金流服務系統在過去一段時間內皆處於回應緩慢的狀態。

OpenTelemetry 是一套 可觀測性(Observability) 框架,用來 產生、收集與匯出 分散式系統的 Telemetry。它提供了一套名為 OpenTelemetry Protocol(OTLP) 的標準,用來定義 Telemetry 的資料結構、API 相關規範等,目的是要提供與供應商無關的標準化 Telemetry 工具。
OpenTelemetry 著重於標準化,因此支援多種程式語言,這對微服務架構尤為重要,因為每個服務可以使用不同的技術進行開發,透過它即可產生相同格式的資料,不僅如此,這些產生出來的 Telemetry 可以 匯出 到其他工具進行分析,如:Prometheus、ELK Stack 等,展現了相當出色的整合能力。
補充:OpenTelemetry 是 CNCF 所孵化的項目。
OpenTelemetry 整體架構如下圖所示:
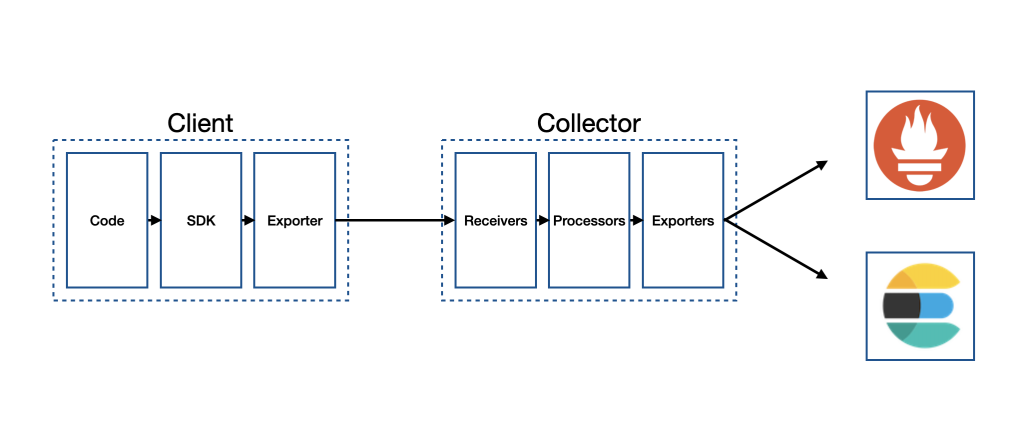
從圖中可以看出,Client 會在 程式碼(Code) 使用 SDK 來產生 Telemetry,並將產生後的資料匯出至 收集器(Collector),Collector 會有 接收器(Receiver) 來接收 Telemetry,並經由 處理器(Processor) 對資料進行處理,最後再透過 匯出器(Exporter) 將資料匯出至 Prometheus、Elasticsearch 等系統。
補充:事實上,Client 可以直接將 Telemetry 透過 Exporter 匯出到其他系統,不一定需要 Collector,不過在較複雜的情境下,還是建議使用 Collector 來收集、處理 Telemetry,會更容易管理。
前面有提到 Trace 可以幫助我們追蹤一次請求處理的過程,那麼要怎麼讓各服務之間知道現在處理的任務是屬於哪一個請求呢?OpenTelemetry 提出了 上下文傳遞(Context Propagation) 的概念,將該筆請求相關的 Context 傳遞給相關的服務,使每個服務都可以理解這個請求的起源與路徑,最終就能將整個請求週期的過程關聯起來。那麼 Context 是什麼東西?為什麼能幫助我們將這些碎片化的資訊關聯起來呢?這就必須提到一個重要的角色 - 跨度(Span)。
Span 是整個 Trace 過程中最小的單元,它表示某個操作的特定時間段,一個 Trace 會由數個 Span 組成。裡面會包含以下訊息:
Unset、Error 與 Ok。注意:Status 的設計容易造成混淆,在一般情況下,一個 Span 完成且沒有發生錯誤,Status 會是
Unset,而Ok代表開發者手動標記此 Span 完成,在實務上很少需要這麼做。
假如有一段 Trace 如下圖所示:
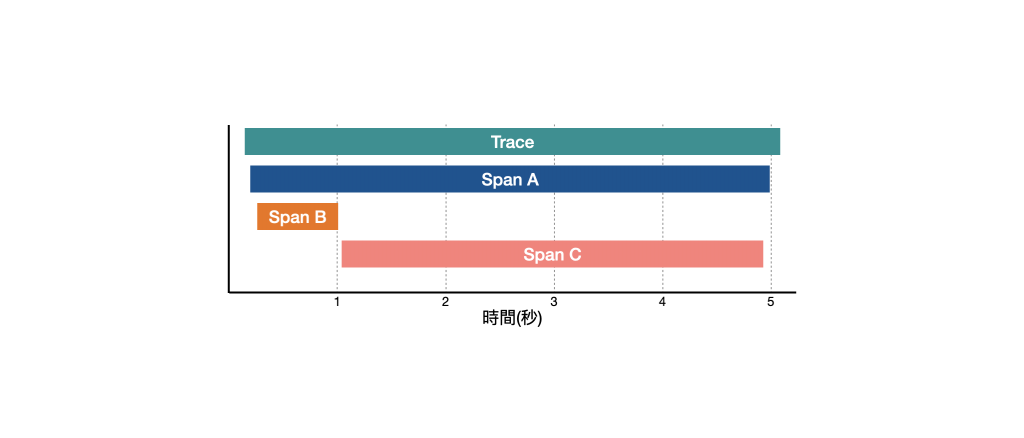
Span A 為 Root Span,Span B 與 Span C 為 Span A 的 Child Span,當執行 Span A 時,會先進入 Span B 的處理,這時就會將 Context 帶給處理 Span B 的服務建立關聯,待 Span B 處理完畢,Span A 緊接著進入 Span C 的處理,這時同樣會將 Context 帶給處理 Span C 的服務建立關聯,待 Span C 處理完畢,Span A 緊接著完成任務,結束整個 Trace 週期。
從這張圖表可以發現整個 Trace 週期花了 5 秒左右的時間才完成,整個請求週期的入口點為處理 Root Span 的服務,但仔細觀察可以發現,Span C 花費了約 4 秒的時間,幾乎佔據了整個週期所花費的時間,這就可以針對 Span C 的服務做更進一步的效能優化。

Grafana Tempo 是一個高效、可擴展的分佈式追蹤系統,專門設計用來收集、儲存及查詢分佈式應用程式中的Trace 資料。Tempo 是由 Grafana Labs 開發的,主要用來與 OpenTelemetry 等工具整合,讓使用者能夠在 Grafana 這樣的視覺化工具中查看、分析應用程式的效能。另外值得一提的是它僅依賴 物件儲存(Object Storage) 即可運作,如:S3、GCS、硬碟等。
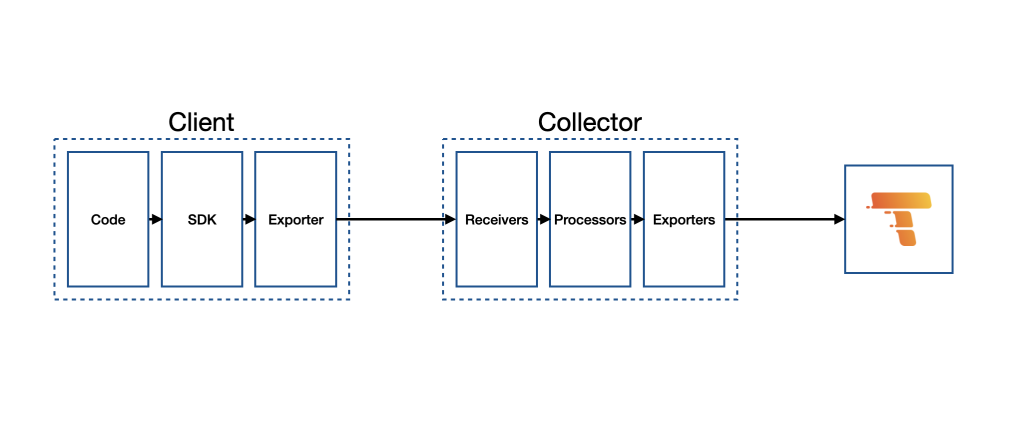
與 OpenTelemetry 結合的整體架構如下圖所示,可以看到由 Client 端產生 Telemetry 後,會先進入 OpenTelemetry Collector,再匯出至 Grafana Tempo 中:
Grafana Tempo 官方有提供非常豐富的範例資源,我們可以利用其資源快速架設 OpenTelemetry Collector、Grafana Tempo 與 Grafana,省去了從零開始的麻煩。首先,透過下方指令將 Grafana Tempo 的 Git Repository 下載下來:
$ git clone https://github.com/grafana/tempo.git
下載完之後,透過下方指令將目錄移動到 otel-collector:
$ cd tempo/example/docker-compose/otel-collector
在 otel-collector.yaml 中,將 receivers 的 grpc endpoint 設定為 0.0.0.0:4317:
receivers:
otlp:
protocols:
grpc:
endpoint: '0.0.0.0:4317'
# ...
接著,打開 docker-compose.yml 將 otel-collector 的 port 補上 4317:4317,並將 Image 更換成 otel/opentelemetry-collector-contrib:
# ...
otel-collector:
image: otel/opentelemetry-collector-contrib:0.107.0
command: [ "--config=/etc/otel-collector.yaml" ]
volumes:
- ./otel-collector.yaml:/etc/otel-collector.yaml
ports:
- 4317:4317
# ...
補充:OpenTelemetry 官方使用的 Image 為
otel/opentelemetry-collector-contrib。
最後,透過下方指令啟動各個服務:
$ docker-compose up -d
待服務啟動完畢後,透過瀏覽器開啟 http://localhost:3000,會看到 Grafana 的頁面:
打開左側選單並點選「Explore」頁面:
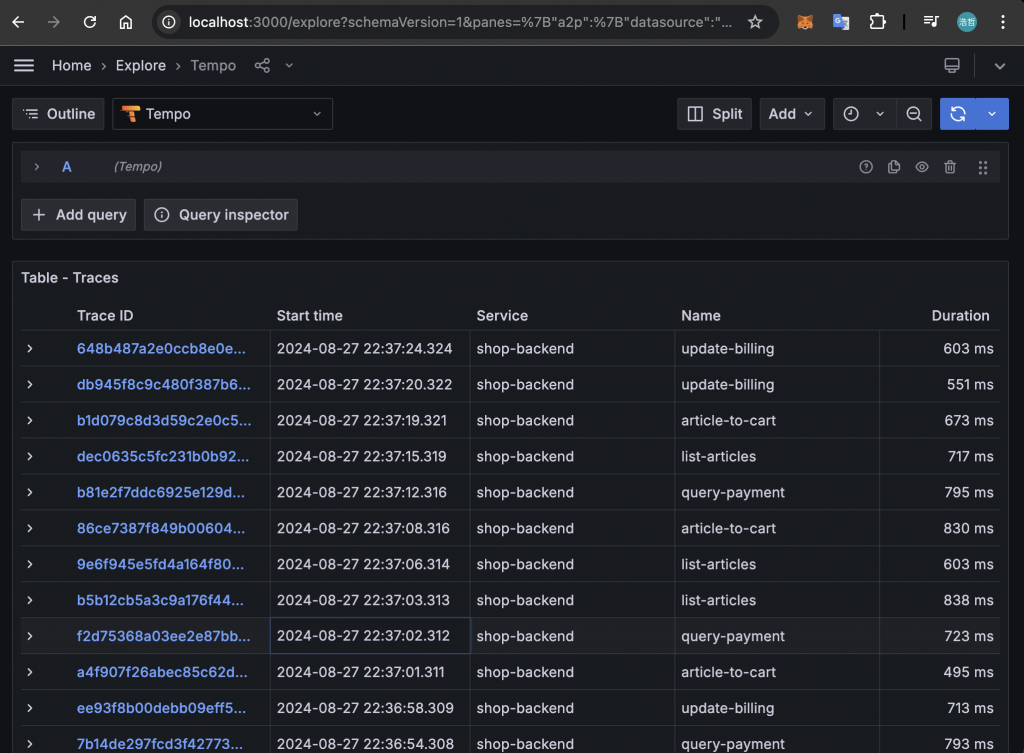
在這個頁面內,即可看到啟動時自動產生的 Trace 資料:
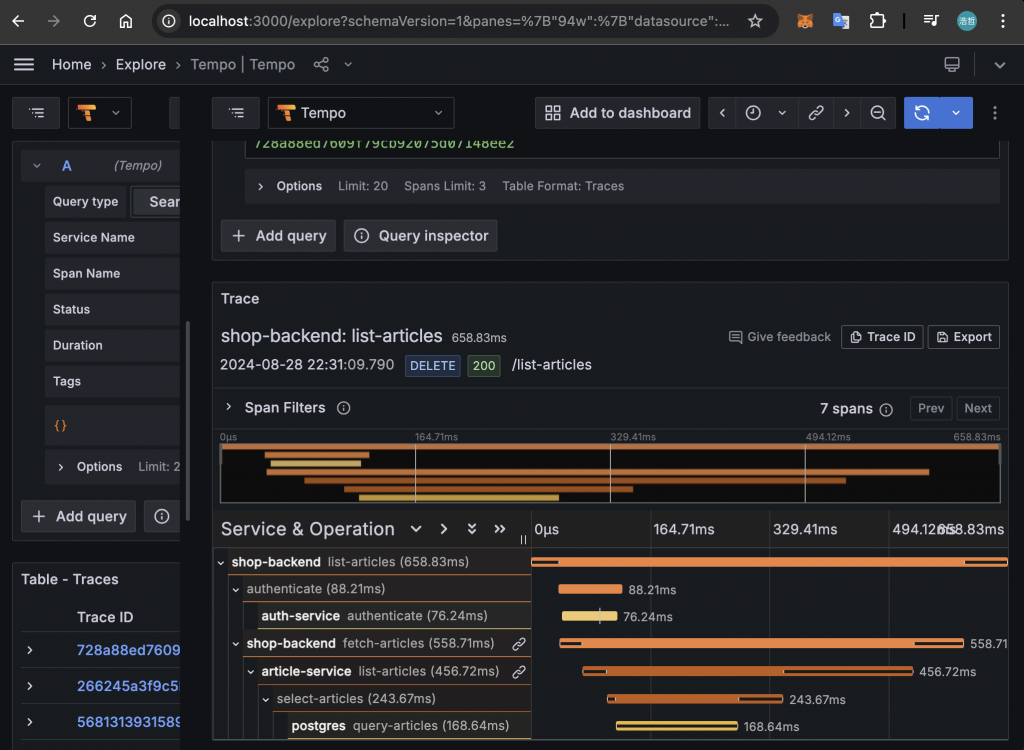
隨機點選一個,會看到 Trace 是由多個 Span 所組成:
在本篇文章中,介紹了 OpenTelemetry 這套 Observability 框架。透過它,我們可以在分散式系統中產生、收集與分析 Trace 等類型的 Telemetry,從而提升系統的可觀測性。文章特別說明了 OpenTelemetry 的架構與運作方式,強調它作為與供應商無關的標準化 Telemetry 工具的重要性。文章還提到了多種可與之整合的工具。最後,展示了如何使用 OpenTelemetry Collector、Grafana Tempo 與 Grafana 將 Trace 資料透過視覺化工具呈現。
下一篇文章將會介紹如何在 NestJS 服務中使用 OpenTelemetry 提供的 SDK 來產生 Trace,並通過上述工具進行觀測,敬請期待!


 iThome鐵人賽
iThome鐵人賽